
Adobe’s Bridge application has a very handy built-in file renaming utility. If you need to add a suffix, a numeric prefix or do a simple string substitution it’s ready and waiting just a keystroke away…
But for more complex string substitutions regex (from REGular EXpressions) come to the rescue!
Here’s a simple problem – you need to rename the first 6 characters of a series of files with a consistent file naming convention…
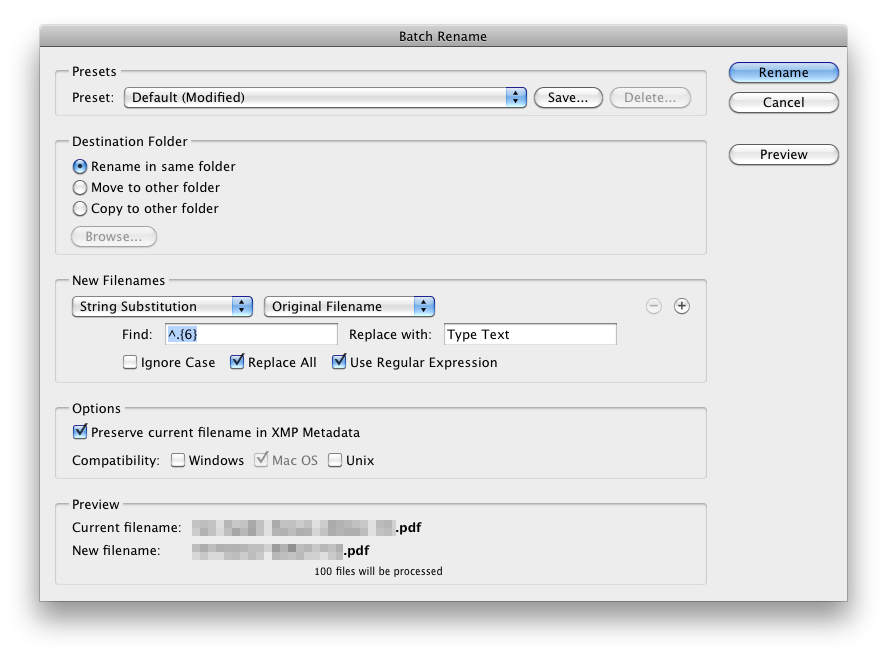
Fire up the batch renaming dialogue ([SHIFT]+[CMD]+R on a mac) – it’s under the Tools menu. Select your files, choose String Substitution from the dropdown, and check Replace All and Use Regular Expression as in the screenshot below.
The magic regex is in the Find field:
^.{6}
Explained
The “^” (a caret AKA “up-arrow”, “chevron”, “control character”) denotes the beginning of the search; the dot “.” denotes any kind of character and finally the “{6}” means six of.
Easy peasy.
You want more…?
Have a look at my follow-up post with more examples of RegEx in Adobe Bridge.
Last updated on 20th December 2018
26th December 2014 at 9:32 pm
Was about to give up on any kind of wildcard support. Kept trying to do it the way I would have done it on DOS years ago (with the ? character.) Thank you so much!
25th October 2015 at 9:36 pm
Just what I was looking for… Thanks SO MUCH!!
5th December 2015 at 1:41 am
It helped me a lot.
Thank you.
15th August 2016 at 1:32 am
This is very nearly what I’m looking for (and the best explained article I’ve found on regex so far!). I’d like to keep the first 6 characters and delete the rest. Do you know how I’d do that? Thanks in advance. 🙂
23rd August 2016 at 1:21 pm
Hey Karen – thanks for the compliment! (Sorry I’m slow to answer – been away in a tent in Galicia for a week. Lovely.)
If you’ve not found the answer already here you go…
Find:
^(.{6})(.*)Replace:
$1The find section groups the filename into two parts – defined by the ( parentheses ).
* The first group is the same as in my example – six characters.
* The second group is everything that comes after. (The dot is any character as before – the asterisk means any number of.)
The replace section simply means use the first group and nothing else. (Each group in the find part gets an implicit number that we can use later on. So replacing with $2 would rename with everything after the first group.)
Try it out in a duplicate folder first!
15th May 2017 at 4:42 pm
Hi Gabriel, This is all a little bit over my head, but I have a sense you’re very good at this! I wonder if I can ask for your help too?
I have a client who wants two separate file naming systems. A high res TIF file labelled with “EAN number-Shot number” and then a web team that need the same images in low res, labelled “Description-EAN number-Shot number”.
So I’m thinking if I name all the files with the latter system, including description, can I then use Bridge to remove the description from the web versions? They won’t all be the same length so I can’t search for first 15 characters as you’ve done above. If I was to use a code such as DESC- -DESC to surround the actual description, would I then be able to search for all characters ‘within’ that DESC- -DESC container, replace it with a 0, then do a ‘remove’ of the text string DESC-0-DESC?
I think I have over complicated that, but do you see what I’m trying to achieve?!
Would be extremely grateful for any ideas, otherwise I’ll have 600+ files to manually remove sections of file name from!!
Thanks so much
Helen
16th May 2017 at 7:49 pm
Hi Helen!
Thanks for popping by… I reckon this should be simple enough if you have a consistent marker. In fact it sounds a lot like example #3 on anther page I wrote up “more RegEx renaming in Adobe Bridge“…
Have a look at that…
…then, if the letters “EAN” are consistently separating the description from the reference IDs you could use them as a “string” to be your marker.
Obviously if that exact string (“EAN”) appears more than once in a file name things might get icky.
Try out (on a duplicate folder!) something like this: Find (.*)EAN(.*) Replace EAN$2
If EAN isn’t consistent try a hash symbol, or two hyphens, an @ symbol – anything that will not appear anywhere else in the file names.
Hope this helps!
4th July 2017 at 8:16 pm
Hi Gabriel, I have a specific problem and I was wondering if there is a relatively easy way to deal with it. I have tried to solve it reading the above examples but with no luck. Here is the situation. I have a large number of files going like this 102_14_2202-1_130117_G_300_1, 102_14_2202-1_130117_G_300_2. I want to remove just the 130117 (it stands for the date, but it could be different dates within the batch) which has a standard distance only from the ending of the file name (the beginning of the file name may vary so I assume it has to be done from the end. Forgive my ignorance on the subject but your article was the easiest I found around on the net.
Anyway thanks for the great article!
Regards,
Nikos
5th July 2017 at 6:45 pm
Hi Nikos,
Couple of options for you…
1. By looking at your examples – if you won’t have underscore-six-digits-underscore repeated in the filenames – it’s easy…
Try the following on a duplicate directory:
Find:
_[0-9]{6}_Replace:
(leave this blank, obviously)
That should remove any group of six {6} digits [0-9] within underscores
2. Alternatively, building on that with a search that looks to the end by including a file extension…
Add to the first solution that you want to also look for a follow-on group made up of any 8 characters followed by a file extension. (NB You’ll need to substitute “.jpg” for your file extension). It the replaces the found stuff with a Backreference to the second Group.
Magical geekery. Again – test this carefully yourself on duplicate files!
Find:
(_[0-9]{6}_)(.{8}\.jpg)Replace:
$2While looking into this I’ve found a terrific online RegEx explainer. My second suggestion explained over there: https://regex101.com/r/oefUey/1
6th July 2017 at 8:48 am
Dear Gabriel,
Thanks a million for your help.
Because the dates are always stated with 6 digits the first method you described worked like a charm. I have no words of how helpful that was. Thanks for the link as well, I had a quick look and it seems very explanatory.
Cheers!!!
4th December 2018 at 4:56 am
Dear Gabriel,
I need help trying to compose how to ADD a character
( an underscore ) into a file name that is non-sequential.
77762367AEC.png
99983485GBD.png
65789348JKL.png
needs to become
77762367_AEC.png
99983485_GBD.png
65789348_JKL.png
How do I write the String Substitution to insert an underscore after the 8th character no matter what that character is and not remove anything in the file name?
Thank-you,
Anya
20th December 2018 at 5:20 pm
Hi Anya,
Sorry for the delay! If you still haven’t found a solution for this you could try:
Find
(.{8})(.*)Replace
$1_$2The two sets of round brackets break the names into two groups. The first counts eight “
{8}” of any character “.” the second grabs any number “*” of any character “.” so will capture everything else.In the replace section you’re back referencing these two groups – group 1 “
$1” with the first eight characters and group two, “$2“, with the rest – and simply adding an underscore between them.Try this on a duplicate folder first though please – I don’t want to screw up your files with a typo!
3rd June 2019 at 3:52 pm
Gabriel, this worked like a charm. Thank you very much!
3rd June 2019 at 11:34 pm
My pleasure Tiago!
15th September 2020 at 6:06 am
Hi Gabriel,
I have managed to get my files rename to the following format using Batch Rename (using file creation date and string substitution).
YYYY-MM-DD-HH-MM
However, if there are any duplicate names, they will be rename as following examples.
2020-09-14-21-36 (1).jpg
2020-09-14-21-36 (2).jpg
2020-09-14-21-36.jpg (note: this is the actual first file)
Is there any regular expression that can perform the following outputs?
2020-09-14-21-36 (1).jpg
2020-09-14-21-36 (2).jpg
2020-09-14-21-36 (3).jpg
I hope, at least, can change those numbers (1 to 2, 2 to 3) automatically; I don’t mind if I have to manually change the first file to “2020-09-14-21-36 (1).jpg”.
I have been digging on the net for past few days. I am really stuck. Any help is very appreciated.
Thank you,
Whitney
15th September 2020 at 11:49 pm
Hi Whitney,
Afraid I don’t have an answer for you on this. Not right now, anyway…
I’m sure it’s possible but it might need a programmer to solve this. It’s fairly simple stuff but not really my bag I’m afraid.
If this were my problem – and I couldn’t get a dev on it – I’d probably try adding seconds-milliseconds (if available) and/or adding a sequence number after the date-time. Or even tacking the original file name on the end.
Seeing duplicate files named as #1 has always bugged me too. I feel your pain!
I’ll try and have a look tomorrow though…
16th September 2020 at 6:49 pm
Thank you Gabriel,
I am not familiar with regular expression either, but it seems (after searching for days online) to be more designed for pattern matching rather than programming / coding (like manipulating data).
In any case, I have found a workaround solution that I can utilize until there is a simpler method.
Workaround:
1 – change the file names to created date as I previously done
2 – manually select the duplicated files (one set at a time) to run a second pass with another batch rename criteria
3 – manually change the first file to criteria
4 – repeat step 2 and 3 until all duplicated files are renamed to my criteria
It is tedious, but working nonetheless (and still save me a lot of typing). So if you ever run into a simpler solution, please kindly let me know. Once again, thank you.