
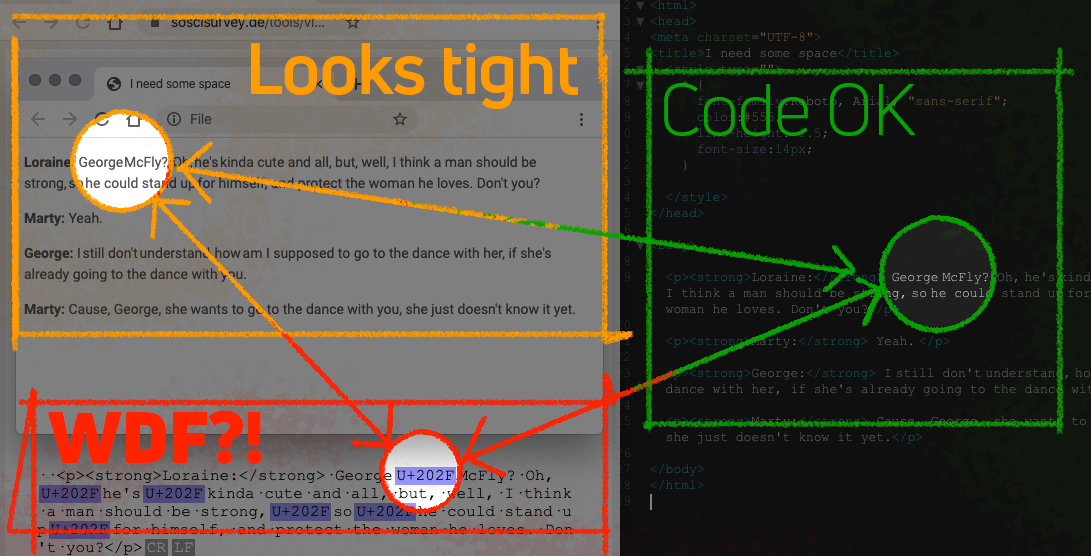
A couple of weeks ago we found this strange problem in an email newsletter: random spaces between words – clearly visible in the source code – were disappearing or very narrow in the rendered email.
Turns out that, somewhere in our collaborative workflow, spaces were being added as the Unicode character for ‘NARROW NO-BREAK SPACE’. [That’s UTF code “U+202F” if you’re interested.] Obviously it’s difficult to spot an invisible character. The way I identified the problem was with this online invisible-character-checking tool that Messrs Google suggested. Once identified there – it was easy to zap all them.
Once again…
Use this invisible-character-checker to find them.
I’m still not sure what caused these special characters to replace regular spaces [so many unanswered questions!] but the problem went away after that week’s extra fuss.
This reminded me of the headaches caused by text encoding mix-ups in the nineties before Unicode – and multilingual websites – were normal. Remember when we had to choose from a list of 8-bit single-byte coded options? No? You lucky *******.
Unicode rocks. Usually.



Leave a Reply